
本文为《用机器学习预测股票的价格》系列文章之 – 特征工程 第1/2部分,阅读本文之前可阅读 python – 用机器学习预测股票的价格 1 – 数据准备。
本文将深入探讨多种时间序列数据类型的特征工程的机制,可以作为股票价格预测建模系统的一部分。内容涵盖基本概念,并提供了有用的代码片段,把原始数据转换为特征,这些特征能直接提供给机器学习算法或者机器学习管道。
许多量化交易者已经在使用基于系统的交易方法或制作图形,他们都有一些特征工程的简单形式,是否实现了这些形式先不考虑。例如:
- 把资产价格序列转换为百分比变化值就是一种特征工程的简单形式
- 绘制价格图形 vs 移动均线是一种特征工程的隐性形式
- 各种技术指标 (RSI, MACD等) 也是特征工程的一些形式
这一过程采用原始输入数据的一列或多列(如,OHLC价格数据、10-Q财务数据、社交媒体情绪指数等),并且把这些列转换为多个工程化特征的列。
特征工程的目的
一般来说,工程特征是机器学习艺术最乏味的一部分,肯定也是最耗费时间、最琐碎的,但也是最有创造性和挑战的(如需要分辨数据是不是脏数据)
特征工程也是最关键环节,最好有行业从业经验。这些人有投资专长,这一点比他们擅长机器学习的技能更重要,他们凭借自已的专业特长能发现特征工程。
特征工程对于数据科学和机器学习来说,更像是艺术,因为每个人对业务的认识不一样,对机器学习的应用场景理解也不一样。把原始数据预先处理为机器学习算法更容易使用的形式,就像很多行业的处理工艺一样,从原矿中提取纯金,特征工程就是从噪声很强的原始数据中提取有价值的“alpha”方案。
实施特征工程的一般原则
特征工程是一个基础性的创新过程,一般来说不应当受到规则或限定的约束,但是还是遵循一些一般性的指导原则:
- 避免出现未来数据(即窥探未来数据,对没有发生的事情赋予了对应的数据),这对于特征工程和预测建模来说,是很容易碰到又要必须避免的问题,即使用到了未来的信息(或者不为人知的数据)对数据进行切片。比如使用next_12_months_returns(未来12个月的回报),但是这也是最经常看到的;又比如使用跨整个时间周期的均值或标准方差来规范数据点(这样做的背后,是把未来信息给了要选择的特征)。如何检查是否使用了未来数据的方法,就是看计算的数据点是不是现在,能否得到准确的相同值;
- 要诚实地对待自己在当下了解到的数据信息,而不是仅仅知道当下发生了什么。例如,股票行情数据有一定时间的滞后,要想锁定带有时间的特征,就要知道在那个时间数据是否已到达;
- 创建特征表格:许多机器学习算法需要每一个输入的特征对于每一个观察都有价值。如果所提供的电子表格中每个特征都是一列,每个观察都是一行,那表中的每个单元格都应该有价值。经常遇到的情况是,表中的某些特征相对于其他一些特征会自然地自我更新,而且更新更加频繁;价格数据的更新基本上是连续的,而产品短期库存数据则是几个星期或几个月才更新。在这样的情况下,可以采用观察最新数据的办法,如LOCF(last observation carried forward (LOCF),向前推进观察最新数据),在更新频率较低的列中每个特都有价值。这种情况也要避免出现未来数据。
- 规避错误的有序数据类型:表示数据的特征是极其重要的,获取有序类型的数据要有业务上的意义。例如,把一周的天数表示为整数1到7,就是经常见到的一种不好的想法,因为这种方法会隐性地把星期五和星期四做非常相似的处理,只是有一点点数字大小的不同,而星期天和星期一是完全不同的,如果星期天是7,那星期一就是1,这样做就有可能忽略数据中有意义的形态。
股票行情数据特征工程实例
首先数据准备,可阅读 python – 用机器学习预测股票的价格 1 – 数据准备 。为了代码完整起见,本文中提供数据准备所必要的代码,
导入必要的工具包
#
#ignorefrom IPython.core.display import HTML,Image
import sys
sys.path.append('/anaconda/')
import config
# HTML('<style>{}</style>'.format(config.CSS))
import Pandas as pd
import csv
import numpy as np读取多只股票数据
target_files = []
with open('D:\SecurityData\watched_stocks_short.csv','r') as csv_file: #watched_stocks.csv, watch_list.csv
csv_reader = csv.reader(csv_file)
for line in csv_reader:
str_line = str(line)
lt,rt = str_line[2:3], str_line[3:9]
if lt == '0':
target_files.append('D:\SecurityData\MD_daily\SZ#'+ rt +'.csv') # 23123-
else:
target_files.append('D:\SecurityData\MD_daily\SH#'+ rt +'.csv') # 18515-
#print(target_files)
print('选定股票的csv文件个数:',len(target_files))
print('target_files 的前 5 个元素:')
print(target_files[0:5])构建股票数据列表
df_list = []
finalmd_filelist = []
for filename in target_files:
try:
headers = ['symbol', 'date', 'open', 'high','low','close','volume','amnt']
dtypes = {'symbol':'str', 'date':'str', 'open':'float', 'high':'float','low':'float','close':'float','volume':'int','amnt':'float'}
parse_dates = ['date'] # 字符型解析为日期型
df = pd.read_csv(filename, sep=',', header=None, names=headers, dtype=dtypes, parse_dates=parse_dates)
#print(df[0:10])
if (len(df) > 480):
del df['amnt']
df_cut = df[(len(df)-481):]
df_cut.reset_index(drop=True,inplace=True)
df_cut = df_cut.set_index(['date','symbol'])
df_list.append(df_cut)
finalmd_filelist.append(filename[25:])
else:
print(f'{filename} 的长度:{len(df)}')
except:
print('error:',filename)
print(df_list[0])
print('df_list_len: ',len(df_list))
#print(finalmd_filelist)
print('finalmd_filelist: ',len(finalmd_filelist))合并选取的股票数据
prices = pd.concat(df_list,axis=0)
num_obs = prices.close.count()
print(num_obs)(以下代码为实施特征工程的代码)
开始为预测股票的机器学习方法实施特征工程
使用已准备好的8只股票的行情数据,创建一个新的dataframe,名称为“features”,用来汇集所有的工程特征。在dataframe中所有的数据统一索引,这样可以在接收到新数据的情况下就可以获得新的特征值。
以下代码是一个特征工程的简单的例子。基于数据创建特征,保存到多个特征列。注意,如果计算公式没有给出每行索引值的有效值,一般用空值替代。
features = pd.DataFrame(index=prices.index).sort_index()
features['f01'] = prices.close/prices.open-1 # daily return
features['f02'] = prices.open/prices.groupby(level='symbol').close.shift(1)-1
print(features.tail())以上代码的运行结果如下图所示:


注意:
命名每一个特征的命名方式,要把每个特征表示的意义记录下来,而不是使用描述性的列名称,理由有以下三个方面:(1) 描述性名称太长,用起来很麻烦;(2) 描述性名称很少能真正的特征本身的含义;(3) 创建抽象名称通常可以有建模人解释每一个特征的含义,但使用起来不方便。
按照这种基本的代码编写形态,可以把任何的数据变化作为特征,这就要看自己的业务的特征理解和分析创新能力了!在创建任何特征之前,确定自己的假设是合理的,而无需考虑在某一个数据特征方面可能有更多的变化形态,可以尝试把符合业务逻辑的显著特征做适当的变形,这一点要多尝试并进行比较,才能更好做好特征工程。
与数据特征有关的变换方法
下面描述的一些有关数据特征的转换方法,都是一些常见的方法,– 特别是使用线性或类似准线性模型提取有意义的关系。像股票市值、成交量、收益这样的时间、数值都可以放入日志空间(log space)映射为预测目标,用pandas+numpy就可以很容易地做到。
(1)log – 日志
features['f03'] = prices.volume.apply(np.log) # 日成交量的日志数据
features['f03']代码运行结果如下图所示:

(2)differencing – 计算差异
通常来说,更重要的是要知道一个数值是如何变化的,这比数值本身更重要。diff() 方法将从前一个时期计算数值的变化(即当前数值减去前一个时期的数据)。注意:“groupby”非常重要,如果忽略了groupby 就只能比较不同股票的成交量的差别,这并不是想要的目标。
与前一个交易日的成交量的差异:
# differencing
features['f03'] = prices.groupby(level='symbol').volume.diff()
features['f03'] 运行结果如下图所示:

前50个交易日的成交量的差异:
features['f04'] = prices.groupby(level='symbol').volume.diff(50)
features['f04']运行结果如下图所示:

(3)rate of change – 变化率
用百分比表示变化率是比较常见的方法,Pandas有一个现成的方法pct_change()。但是和上面代码中的groupby一起使用,就会得到奇怪的结果,因此创建自己的lambda函数,代码如下:
pct_chg_fxn = lambda x: x.pct_change()
features['f05'] = prices.groupby(level='symbol').volume.apply(pct_chg_fxn)
features['f05'] 运行结果如下图所示:

(4)Moving Averages 移动均值
有时候使用数值的移动均值作为特征的组成部分也是很好的选择。如果想把某个数值的敏感性降到最小,可以使用数值本身;或者,数值与其最新的移动均值相比较。另外,由于dataframe有多只股票的信息,所以需要使用groupby,还要用lambda函数规避错误,应对这种情况还有其他方法,但这是最清晰的方法。
成交量的5日移动均值:
# 成交量的5日移动均值日志
ma_5 = lambda x: x.rolling(5).mean()
features['f06'] = prices.volume.groupby(level='symbol').apply(ma_5).apply(np.log)
features['f06']运行结果如下:

成交量的200天移动均值:
ma_200 = lambda x: x.rolling(200).mean()
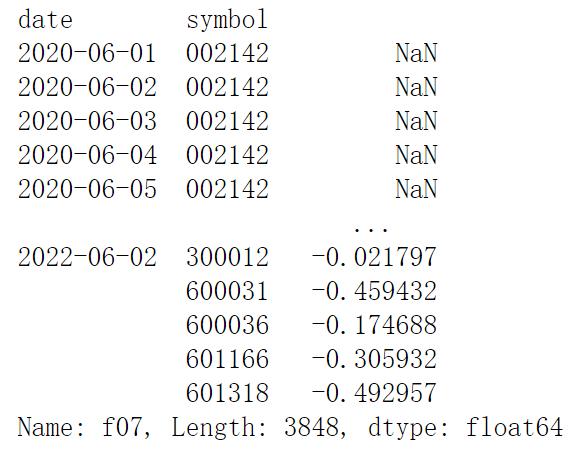
features['f07'] = prices.volume/ prices.volume.groupby(level='symbol').apply(ma_200)-1
features['f07']运行结果如下:
成交量的50天指数移动均值:
ema_50 = lambda x: x.ewm(span=50).mean()
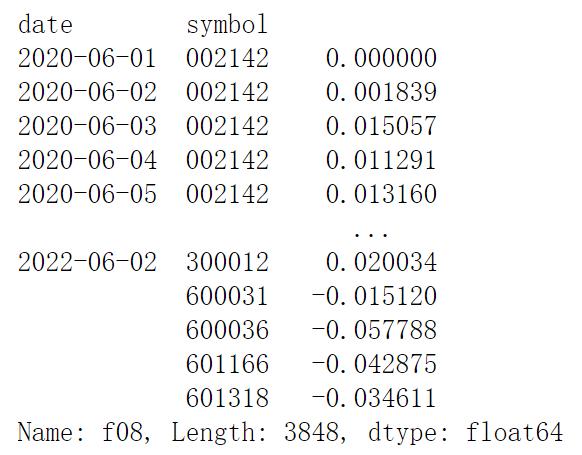
features['f08'] = prices.close/ prices.close.groupby(level='symbol').apply(ema_50)-1
features['f08']运行结果如下:
移动时间窗口是一个很重要但也很主观的数值,所以应该尝试某个范围内的多个合理数值。个人经验表明,使用数值的对数增加值比线性增加值更好;也就是说,使用[5,10,20,40,80,160]比[10,20,30,40…,100] 比较好。例如,90和100真的很相似,而10和20的差别很大;因此,如果选择线性间隔的数值,数值范围的末尾数字越大,那就比末最新值越低的机会更多,在更大的数值范围内出现过度拟合的可能性也将增加。
(5)Z-Scores
Z-Score是转换金融时间序列数据常用的方法,可以为这种方法定义一个通用的lambda函数,需要时使用。重要的是,可以把价格差异非常大的股票混在一起,只要所采用的方法是判断任何运动在统计上的显著性就可以。
zscore_fxn = lambda x: (x - x.mean()) / x.std()
features['f09'] =prices.groupby(level='symbol').close.apply(zscore_fxn)
features.f09.unstack().plot.kde(title='Z-Scores (not quite accurate)')运行结果如下:
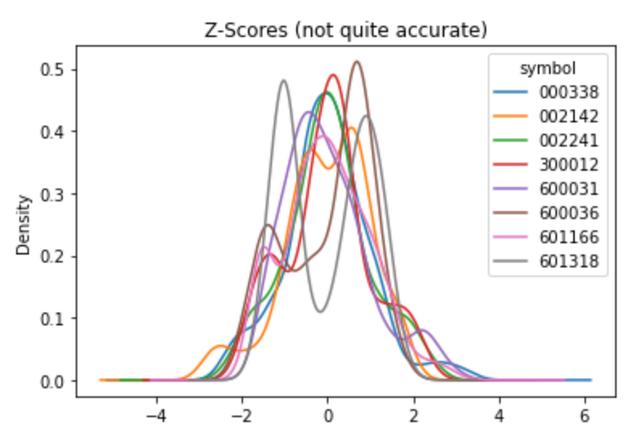
但是上面的代码段有一个微小但很严重的bug,它使用了整个时间窗口的均值和整个时间窗口的标准方差来计算每个数据点,这就意味着涉及到了未来的数据,这一特征就有潜在的重大风险(这种方法在样本内数据上运行很好,但在样本外数据上就失败了)。因此,必须修改这个bug,
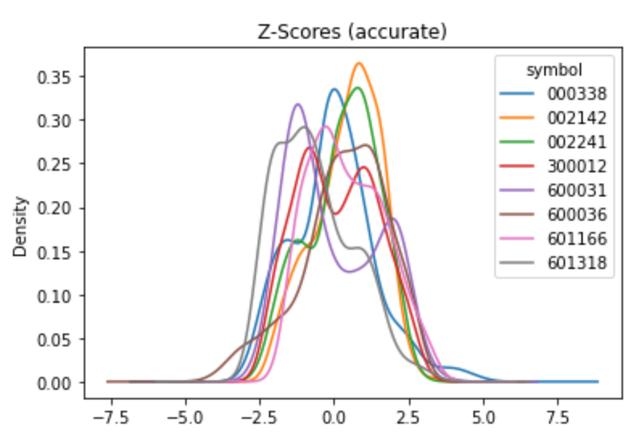
zscore_fun_improved = lambda x: (x - x.rolling(window=200, min_periods=20).mean())/ x.rolling(window=200, min_periods=20).std()
features['f10'] =prices.groupby(level='symbol').close.apply(zscore_fun_improved)
features.f10.unstack().plot.kde(title='Z-Scores (accurate)')修改后的运行结果如下:
(6)Percentile 百分比
百分比这种变换方法一般用的少,但也很有用。可以用pandas工具包做适当的变换,但需要一定的技巧。以下代码返回每个数值的成交量百分比排名(从0.00到1.00),这是与最近200个交易日相比;需要在lambda函数中套入lambda函数,才能正确地处理,这样做要小心。
rollrank_fxn = lambda x: x.rolling(200,min_periods=20).apply(lambda x: pd.Series(x).rank(pct=True)[0])
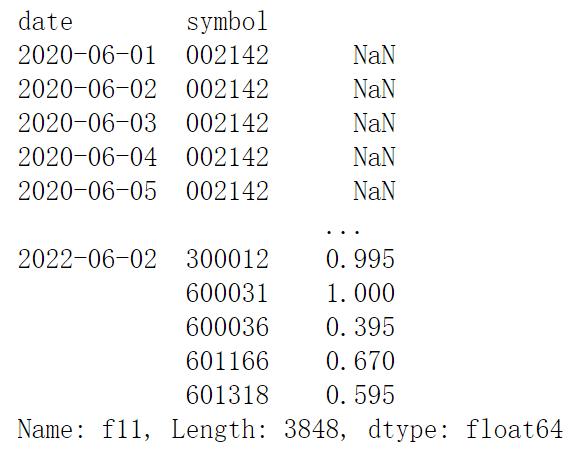
features['f11'] = prices.groupby(level='symbol').volume.apply(rollrank_fxn)
features['f11']运行结果如下:
用同样的方式还可以对每个股票进行跨季度排名,也就是说,在同一天该股票在所有的股票中的排名位置在哪儿,而不是某只股票在所有的交易日的排名在哪儿。以下例子只有两只股票,虽然不是很有实用价值,但是在现实环境中很有用。在这个例子中,也利用此前的特征(相对成交量)来比较在指定的交易日该股票在正常的交易范围内交易是最多的。注意:在进行排名之前要用dropna() ,因为 rank 并不能很好的处理空值。
features['f12'] = features['f07'].dropna().groupby(level='date').rank(pct=True)
features['f12']运行结果如下:

本文未完……
《用机器学习预测股票的价格》系列文章之 – 特征工程 第2/2部分,将后续发布,敬请关注。

全国网约车司机交流群,交流经验,添加 微信:gua561 备注:加群!
如若转载,请注明出处:https://www.wyczc.com/13367.html